The DNA (deoxyribonucleic acid) is the biomolecule that contains all the information necessary to generate an organism and maintain its functioning. It is made up of units called nucleotides, made up of a phosphate group, a five-carbon sugar molecule, and a nitrogenous base..
There are four nitrogenous bases: adenine (A), cytosine (C), guanine (G), and thymine (T). Adenine always pairs with thymine and guanine with cytosine. The message contained in the DNA strand is transformed into a messenger RNA and this participates in the synthesis of proteins.

DNA is an extremely stable molecule, negatively charged at physiological pH, that associates with positive proteins (histones) to efficiently compact in the nucleus of eukaryotic cells. A long chain of DNA, together with various associated proteins forms a chromosome.
Article index
In 1953, the American James Watson and the British Francis Crick managed to elucidate the three-dimensional structure of DNA, thanks to the work in crystallography carried out by Rosalind Franklin and Maurice Wilkins. They also based their conclusions on the work of other authors.
When DNA is exposed to X-rays, a diffraction pattern is formed that can be used to infer the structure of the molecule: a helix of two antiparallel chains that rotate to the right, where both chains are joined by hydrogen bonds between the bases. . The pattern obtained was the following:

The structure can be assumed following Bragg's laws of diffraction: when an object is interposed in the middle of an X-ray beam, it is reflected, since the electrons of the object interact with the beam..
On April 25, 1953, the results of Watson and Crick were published in the prestigious magazine Nature, in an article of only two pages entitled “Molecular structure of nucleic acids”, Which would completely revolutionize the field of biology.
Thanks to this discovery, the researchers received the Nobel Prize in medicine in 1962, with the exception of Franklin who died before the delivery. Currently this discovery is one of the great exponents of the success of the scientific method to acquire new knowledge.
The DNA molecule is made up of nucleotides, units made up of a five-carbon sugar attached to a phosphate group and a nitrogenous base. The type of sugar found in DNA is the deoxyribose type and hence its name, deoxyribonucleic acid..
To form the chain, the nucleotides are covalently linked by a phosphodiester-type bond through a 3'-hydroxyl group (-OH) from a sugar and the 5'-phosphapho of the next nucleotide.
Nucleotides should not be confused with nucleosides. The latter refers to the part of the nucleotide formed only by pentose (sugar) and the nitrogenous base.
DNA is made up of four types of nitrogenous bases: adenine (A), cytosine (C), guanine (G) and thymine (T).
Nitrogen bases are classified into two categories: purines and pyrimidines. The first group consists of a ring of five atoms attached to another ring of six, while the pyrimidines are composed of a single ring.
Of the bases mentioned, adenine and guanine are derived from purines. In contrast, to the group of pyrimidines belong thymine, cytosine and uracil (present in the RNA molecule).
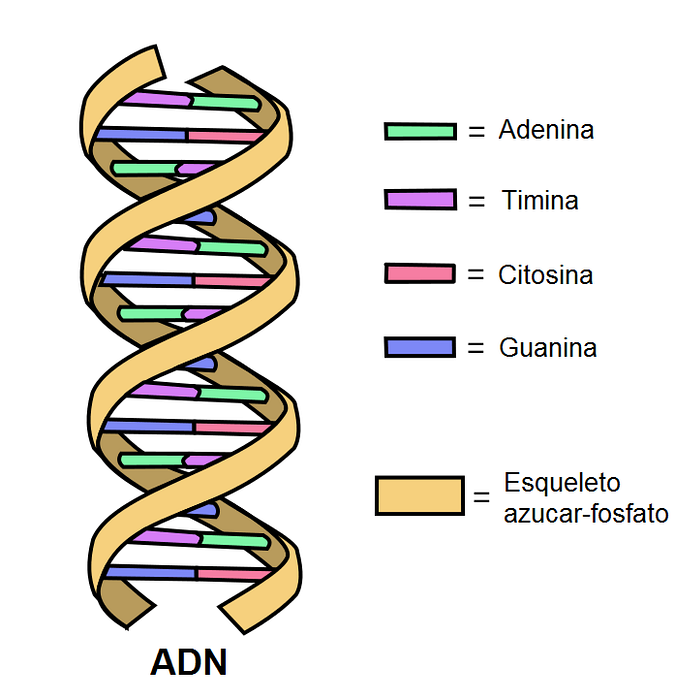
A DNA molecule is made up of two chains of nucleotides. This "chain" is known as a DNA strand..
The two strands are linked by hydrogen bonds between the complementary bases. Nitrogen bases are covalently linked to a backbone of sugars and phosphates.
Each nucleotide located on one strand can be coupled with another specific nucleotide on the other strand, to form the well-known double helix. In order to form an efficient structure, A always couples with T by means of two hydrogen bonds, and G with C by three bridges..
If we study the proportions of nitrogenous bases in DNA, we will find that the amount of A is identical to the amount of T and the same with G and C. This pattern is known as Chargaff's law.
This pairing is energetically favorable, since it allows a similar width to be preserved throughout the structure, maintaining a similar distance along the sugar-phosphate backbone molecule. Note that a base of a ring mates with one of a ring.
It is suggested that the double helix is composed of 10.4 nucleotides per turn, separated by a center-to-center distance of 3.4 nanometers. The rolling process gives rise to the formation of grooves in the structure, being able to observe a larger and a smaller groove.
The grooves arise because the glycosidic bonds in the base pairs are not opposite each other, with respect to their diameter. Pyrimidine O-2 and purine N-3 are found in the minor groove, while the major groove is located in the opposite region.
If we use the analogy of a ladder, the rungs consist of the complementary base pairs to each other, while the skeleton corresponds to the two grab rails..
The ends of the DNA molecule are not the same, which is why we speak of a “polarity”. One of its ends, the 3 ', carries an -OH group, while the 5' end has the free phosphate group.
The two strands are located antiparallel, which means that they are located opposite to their polarities, as follows:
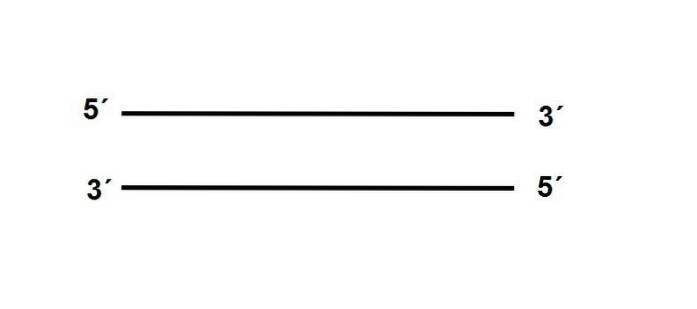
In addition, the sequence of one of the strands must be complementary to its partner, if it is a position there is A, in the antiparallel strand there must be a T.
In each human cell there are approximately two meters of DNA that must be packaged efficiently.
The strand must be compacted so that it can be contained in a microscopic nucleus of 6 μm in diameter that occupies only 10% of the cell volume. This is possible thanks to the following levels of compaction:
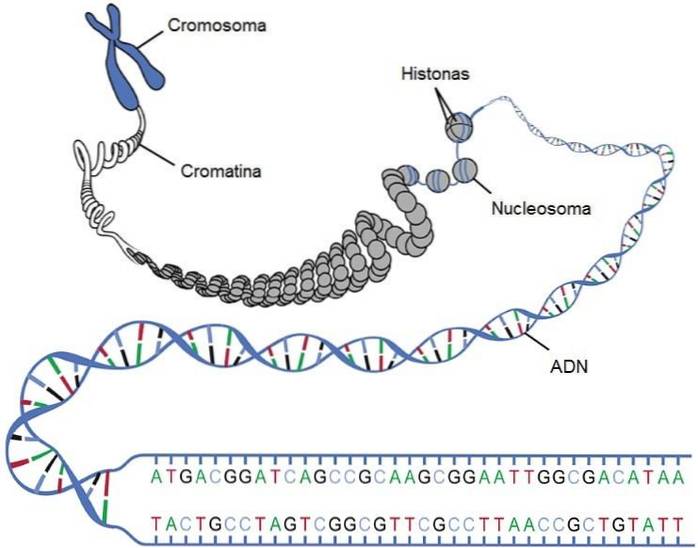
In eukaryotes there are proteins called histones, which have the ability to bind to the DNA molecule, being the first level of compaction of the strand. Histones have positive charges to be able to interact with the negative charges of DNA, provided by phosphates.
Histones are proteins so important to eukaryotic organisms that they have been virtually unchanged in the course of evolution - remembering that a low rate of mutations indicates that the selective pressures on that molecule are strong. Histone damage could lead to defective DNA compaction.
Histones can be biochemically modified and this process modifies the level of compaction of the genetic material.
When histones are "hypoacetylated" chromatin is more condensed, since acetylated forms neutralize the positive charges of lysines (positively charged amino acids) in the protein..
The DNA strand coils into the histones and they form structures that resemble the beads on a pearl necklace, called nucleosomes. At the heart of this structure are two copies of each type of histone: H2A, H2B, H3, and H4. The union of the different histones is called the "histone octamer".
The octamer is surrounded by about 146 base pairs, circling less than two times. A human diploid cell contains approximately 6.4 x 109 nucleotides that are organized into 30 million nucleosomes.
Organization in nucleosomes allows DNA to be compacted to more than a third of its original length.
In a process of extraction of genetic material under physiological conditions, it is observed that nucleosomes are arranged in a 30-nanometer fiber.
Chromosomes are the functional unit of heredity, whose function is to carry the genes of an individual. A gene is a segment of DNA that contains the information to synthesize a protein (or a series of proteins). However, there are also genes that code for regulatory elements, such as RNA.
All human cells (except gametes and red blood cells) have two copies of each chromosome, one inherited from the father and the other from the mother.
Chromosomes are structures made up of a long linear piece of DNA associated with the protein complexes mentioned above. Normally in eukaryotes, all the genetic material included in the nucleus is divided into a series of chromosomes.
Prokaryotes are organisms that lack a nucleus. In these species, the genetic material is highly coiled together with alkaline low molecular weight proteins. In this way, the DNA is compacted and located in a central region in the bacterium..
Some authors often call this structure "bacterial chromosome", although it does not have the same characteristics of a eukaryotic chromosome.
Not all species of organisms contain the same amount of DNA. In fact, this value is highly variable between species and there is no relationship between the amount of DNA and the complexity of the organism. This contradiction is known as the "C value paradox".
The logical reasoning would be to intuit that the more complex the organism is, the more DNA it has. However, this is not true in nature..
For example the lungfish genome Protopterus aethiopicus It is 132 pg in size (DNA can be quantified in picograms = pg) while the human genome weighs only 3.5 pg.
It must be remembered that not all the DNA of an organism codes for proteins, a large amount of this is related to regulatory elements and with the different types of RNA.
The Watson and Crick model, deduced from the X-ray diffraction patterns, is known as the B-DNA helix and is the “traditional” and best-known model. However, there are two other different forms, called A-DNA and Z-DNA..
The "A" variant turns to the right, just like the B-DNA, but is shorter and wider. This form appears when relative humidity decreases.
The A-DNA rotates every 11 base pairs, the major groove is narrower and deeper than the B-DNA. With respect to the minor groove, this is more superficial and wide.
The third variant is Z-DNA. It is the narrowest form, formed by a group of hexanucleotides organized in a duplex of antiparallel chains. One of the most outstanding characteristics of this shape is that it turns to the left, while the other two ways do it to the right.
Z-DNA appears when there are short sequences of pyrimidines and purines alternating with each other. The major sulcus is flat and the minor is narrow and deeper, compared to the B-DNA.
Although under physiological conditions the DNA molecule is mostly in its B form, the existence of the two variants described exposes the flexibility and dynamism of the genetic material..
The DNA molecule contains all the information and instructions necessary for the construction of an organism. The complete set of genetic information in organisms is called genome.
The message is encoded by the "biological alphabet": the four bases mentioned previously, A, T, G and C.
The message can lead to the formation of various types of proteins or code for some regulatory element. The process by which these databases can deliver a message is explained below:
The message encrypted in the four letters A, T, G and C results in a phenotype (not all DNA sequences code for proteins). To achieve this, DNA must replicate itself in each process of cell division..
DNA replication is semi-conservative: one strand serves as a template for the formation of the new daughter molecule. Different enzymes catalyze replication, including DNA primase, DNA helicase, DNA ligase, and topoisomerase..
Subsequently, the message - written in a base sequence language - must be transmitted to an intermediate molecule: RNA (ribonucleic acid). This process is called transcription..
For transcription to occur, different enzymes must participate, including RNA polymerase.
This enzyme is responsible for copying the message of DNA and converting it into a messenger RNA molecule. In other words, the goal of transcription is to obtain the messenger.
Finally, the translation of the message into messenger RNA molecules occurs, thanks to the ribosomes.
These structures take the messenger RNA and together with the translation machinery form the specified protein..
The message is read in "triplets" or groups of three letters that specify for an amino acid - the building blocks of proteins. It is possible to decipher the message of the triplets since the genetic code has already been fully revealed.
Translation always begins with the amino acid methionine, which is encoded by the starting triplet: AUG. The "U" represents the base uracil and is characteristic of RNA and supplants thymine.
For example, if the messenger RNA has the following sequence: AUG CCU CUU UUU UUA, it is translated into the following amino acids: methionine, proline, leucine, phenylalanine, and phenylalanine. Note that two triplets - in this case UUU and UUA - may code for the same amino acid: phenylalanine.
Due to this property, it is said that the genetic code is degenerate, since an amino acid is encoded by more than one sequence of triplets, except for the amino acid methionine, which dictates the start of translation..
The process is stopped with specific stop or stop triplets: UAA, UAG, and UGA. They are known under the names of ocher, amber and opal, respectively. When the ribosome detects them, they can no longer add any more amino acids to the chain.
Nucleic acids are acidic in nature and are soluble in water (hydrophilic). The formation of hydrogen bonds between the phosphate groups and the hydroxyl groups of pentoses with water can occur. It is negatively charged at physiological pH.
DNA solutions are highly viscous, due to the deformation resistance capacity of the double helix, which is very rigid. Viscosity decreases if nucleic acid is single-stranded.
They are highly stable molecules. Logically, this characteristic must be indispensable in the structures that carry genetic information. Compared to RNA, DNA is much more stable because it lacks a hydroxyl group.
DNA can be heat denatured, meaning the strands separate when the molecule is exposed to high temperatures.
The amount of heat that must be applied depends on the G-C percentage of the molecule, because these bases are linked by three hydrogen bonds, increasing the resistance to separation..
Regarding the absorption of light, they have a peak at 260 nanometers, which increases if the nucleic acid is single-stranded, since the nucleotide rings are exposed and these are responsible for the absorption..
According to Lazcano et al. 1988 DNA emerges in transition stages from RNA, being one of the most important events in the history of life.
The authors propose three stages: a first period where there were molecules similar to nucleic acids, later the genomes were made up of RNA and as the last stage the double-band DNA genomes appeared..
Some evidence supports the theory of a primary world based on RNA. First, protein synthesis can occur in the absence of DNA, but not when RNA is missing. Furthermore, RNA molecules with catalytic properties have been discovered..
Regarding the synthesis of deoxyribonucleotides (present in DNA) they always come from the reduction of ribonucleotides (present in RNA).
The evolutionary innovation of a DNA molecule must have required the presence of enzymes that synthesize DNA precursors and participate in the reverse transcription of RNA.
By studying current enzymes, it can be concluded that these proteins have evolved several times and that the transition from RNA to DNA is more complex than previously believed, including processes of transfer and loss of genes and non-orthologous replacements..
DNA sequencing consists of elucidating the sequence of the DNA strand in terms of the four bases that compose it.
Knowledge of this sequence is of utmost importance in the biological sciences. It can be used to discriminate between two morphologically very similar species, to detect diseases, pathologies or parasites and even has a forensic applicability.
Sanger sequencing was developed in the 1900s and is the traditional technique for clarifying a sequence. Despite its age, it is a valid method and widely used by researchers.
The method uses DNA polymerase, a highly reliable enzyme that replicates DNA in cells, synthesizing a new strand of DNA using a pre-existing one as a guide. The enzyme requires a first or primer to initiate synthesis. The primer is a small molecule of DNA complementary to the molecule to be sequenced.
In the reaction, nucleotides are added that are going to be incorporated into the new DNA strand by the enzyme.
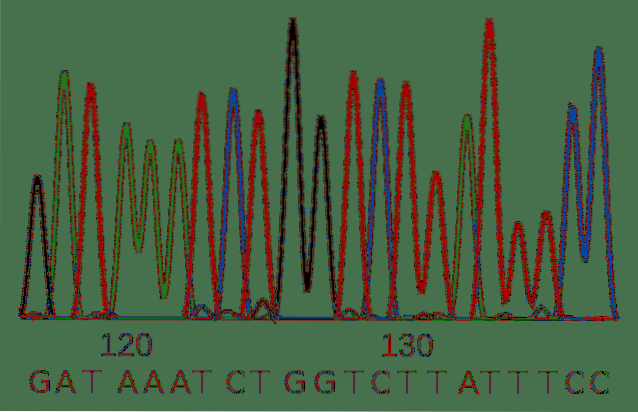
In addition to the "traditional" nucleotides, the method includes a series of dideoxynucleotides for each of the bases. They differ from standard nucleotides in two characteristics: structurally they do not allow DNA polymerase to add more nucleotides to the daughter strand and they have a different fluorescent marker for each base.
The result is a variety of DNA molecules of different lengths, since the dideoxynucleotides were incorporated at random and stopped the replication process at different stages..
This variety of molecules can be separated according to their length and the identity of the nucleotides is read by means of the emission of light from the fluorescent label..
Sequencing techniques developed in recent years allow massive analysis of millions of samples simultaneously.
Among the most outstanding methods are pyrosequencing, sequencing by synthesis, sequencing by ligation and next-generation sequencing by Ion Torrent..



Yet No Comments