The ungrouped data are those that, obtained from a study, are not yet organized by classes. When it is a manageable number of data, usually 20 or less, and there are few different data, it can be treated as not grouped and valuable information extracted from it.
The non-grouped data come as is from the survey or the study carried out to obtain them and therefore lack processing. Let's see some examples:

-Results of an IQ test on 20 random students from a university. The data obtained were the following:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112,106
-Ages of 20 employees of a certain popular coffee shop:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-The final grade average of 10 students in a mathematics class:
3.2; 3.1; 2.4; 4.0; 3.5; 3.0; 3.5; 3.8; 4.2; 4.9
Article index
There are three important properties that characterize a set of statistical data, whether or not they are grouped, which are:
-Position, which is the tendency of the data to cluster around certain values.
-Dispersion, an indication of how scattered or scattered the data is around a given value.
-Shape, It refers to the way in which the data are distributed, which is appreciated when a graph of the same is constructed. There are very symmetrical curves and also skewed, either to the left or to the right of a certain central value.
For each of these properties there are a series of measures that describe them. Once obtained, they provide us with an overview of the behavior of the data:
-The most used position measures are the arithmetic mean or simply mean, the median and the mode.
-Range, variance, and standard deviation are frequently used in dispersion, but they are not the only measures of dispersion..
-And to determine the shape, the mean and median are compared through bias, as will be seen shortly.
-The arithmetic mean, also known as average and denoted as X, it is calculated as follows:
X = (x1 + xtwo + x3 +… Xn) / n
Where x1, xtwo,…. xn, are the data and n is the total of them. In summation notation we have:
-Median is the value that appears in the middle of an ordered sequence of data, so to obtain it, it is necessary to order the data first of all.
If the number of observations is odd, there is no problem in finding the midpoint of the set, but if we have an even number of data, the two central data are searched and averaged.
-Fashion is the most common value observed in the data set. It does not always exist, since it is possible that no value is repeated more frequently than another. There could also be two data with equal frequency, in which case we speak of a bi-modal distribution.
Unlike the previous two measures, the mode can be used with qualitative data.
Let's see how these position measures are calculated with an example:
Suppose you want to determine the arithmetic mean, the median and the mode in the example proposed at the beginning: the ages of 20 employees of a cafeteria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
The half it is calculated simply by adding all the values and dividing by n = 20, which is the total number of data. In this way:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22.3 years.
To find the median you need to sort the dataset first:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
As it is an even number of data, the two central data, highlighted in bold, are taken and averaged. Because they are both 22, the median is 22 years.
Finally, the fashion It is the data that is repeated the most or the one whose frequency is greater, this being 22 years.
The range is simply the difference between the largest and the smallest of the data and allows you to quickly appreciate the variability of the data. But aside, there are other measures of dispersion that offer more information about the distribution of the data..
The variance is denoted as s and is calculated by the expression:
Then to correctly interpret the results, the standard deviation is defined as the square root of the variance, or also the quasi-standard deviation, which is the square root of the quasi-variance:
It is the comparison between the mean X and the median Med:
-If Med = mean X: the data is symmetric.
-When X> Med: skew to the right.
-And if X < Med: los datos sesgan hacia la izquierda.
Find mean, median, mode, range, variance, standard deviation and bias for the results of an IQ test performed on 20 students from a university:
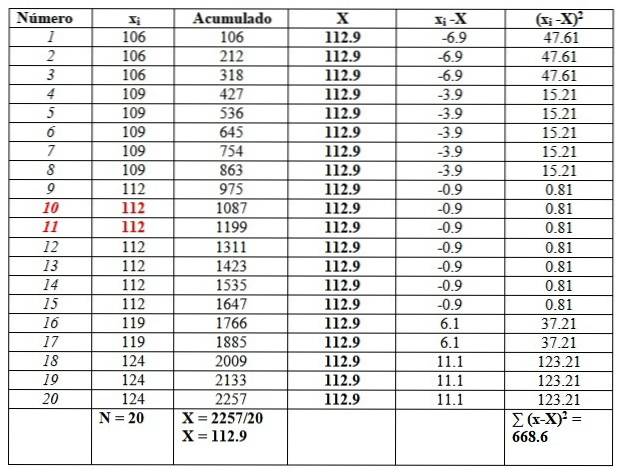
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
We will order the data, since it will be necessary to find the median.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
And we will put them in a table as follows, to facilitate the calculations. The second column entitled "Accumulated" is the sum of the corresponding data plus the previous one..
This column will help to easily find the mean, dividing the last accumulated by the total number of data, as seen at the end of the "Accumulated" column:
X = 112.9
The median is the average of the central data highlighted in red: the number 10 and the number 11. Since they are the same, the median is 112.
Finally, the mode is the value that is repeated the most and is 112, with 7 repetitions..
Regarding the measures of dispersion, the range is:
124-106 = 18.
The variance is obtained by dividing the final result in the right column by n:
s = 668.6 / 20 = 33.42
In this case, the standard deviation is the square root of the variance: √33.42 = 5.8.
For their part, the quasi-variance and quasi-standard deviation values are:
sc= 668.6 / 19 = 35.2
Quasi-standard deviation = √35.2 = 5.9
Finally, the bias is slightly to the right, since the mean 112.9 is greater than the median 112.



Yet No Comments