The F distribution o Fisher-Snedecor distribution is the one used to compare the variances of two different or independent populations, each of which follows a normal distribution.
The distribution that follows the variance of a set of samples from a single normal population is the chi-square distribution (Χtwo) of degree n-1, if each of the samples in the set has n elements.
To compare the variances of two different populations, it is necessary to define a statistical, that is, an auxiliary random variable that allows us to discern whether or not both populations have the same variance.
Said auxiliary variable can be directly the quotient of the sample variances of each population, in which case, if said quotient is close to unity, there is evidence that both populations have similar variances.
Article index
The random variable F or F statistic proposed by Ronald Fisher (1890 - 1962) is the one most frequently used to compare the variances of two populations and is defined as follows:
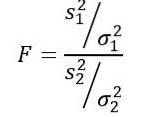
Being stwo the sample variance and σtwo the population variance. To distinguish each of the two population groups, the subscripts 1 and 2 are used respectively..
It is known that the chi-square distribution with (n-1) degrees of freedom is the one that follows the auxiliary variable (or statistical) defined below:
Xtwo = (n-1) stwo / σtwo.
Therefore, the F statistic follows a theoretical distribution given by the following formula:
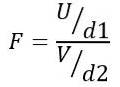
Being OR the chi-square distribution with d1 = n1 - 1 degrees of freedom for population 1 and V the chi-square distribution with d2 = n2 - 1 degrees of freedom for population 2.
The quotient defined in this way is a new probability distribution, known as F distribution with d1 degrees of freedom in the numerator and d2 degrees of freedom in the denominator.
The mean of the F distribution is calculated as follows:
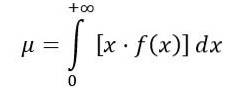
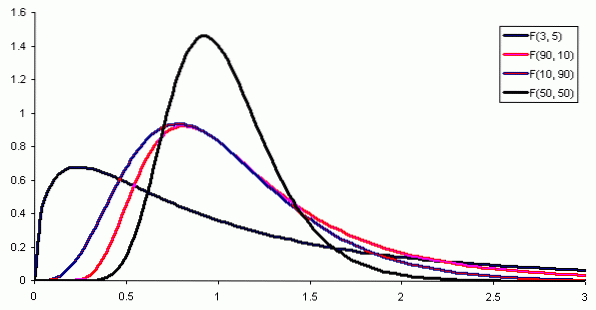
Where f (x) is the probability density of the distribution F, which is shown in figure 1 for various combinations of parameters or degrees of freedom.
We can write the probability density f (x) as a function of the function Γ (gamma function):
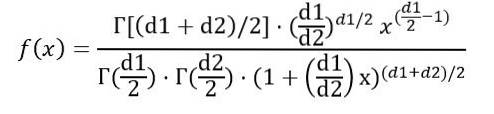
Once the integral indicated above has been carried out, it is concluded that the mean of the F distribution with degrees of freedom (d1, d2) is:
μ = d2 / (d2 - 2) with d2> 2
Where it is noted that, curiously, the mean does not depend on the degrees of freedom d1 of the numerator.
On the other hand, the mode does depend on d1 and d2 and is given by:
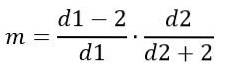
For d1> 2.
The variance σtwo of the F distribution is calculated from the integral:
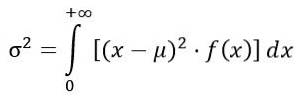
Obtaining:
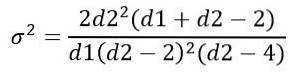
Like other continuous probability distributions that involve complicated functions, the handling of the F distribution is done using tables or software..
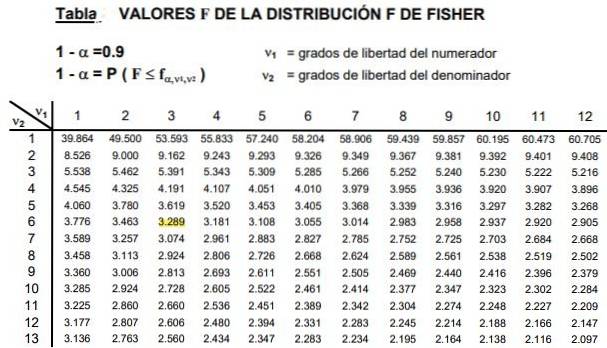
The tables involve the two parameters or degrees of freedom of the F distribution, the column indicates the degree of freedom of the numerator and the row the degree of freedom of the denominator.
Figure 2 shows a section of the table of the F distribution for the case of a significance level of 10%, that is α = 0.1. The value of F is highlighted when d1 = 3 and d2 = 6 with confidence level 1- α = 0.9 that is 90%.
As for the software that handles the F distribution there is a great variety, from spreadsheets such as Excel to specialized packages like minitab, SPSS Y R to name some of the best known.
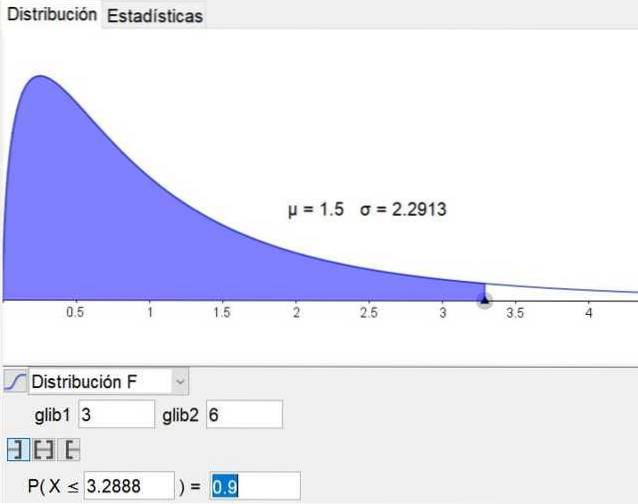
It is noteworthy that the geometry and mathematics software geogebra has a statistical tool that includes the main distributions, including the F distribution. Figure 3 shows the F distribution for the case d1 = 3 and d2 = 6 with confidence level of 90%.
Consider two samples of populations that have the same population variance. If sample 1 has size n1 = 5 and sample 2 has size n2 = 10, determine the theoretical probability that the quotient of their respective variances is less than or equal to 2.
It should be remembered that the F statistic is defined as:
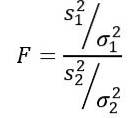
But we are told that the population variances are equal, so for this exercise the following applies:
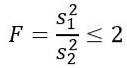
As we want to know the theoretical probability that this quotient of sample variances is less than or equal to 2, we need to know the area under the F distribution between 0 and 2, which can be obtained by tables or software. For this, it must be taken into account that the required F distribution has d1 = n1 - 1 = 5 - 1 = 4 and d2 = n2 - 1 = 10 - 1 = 9, that is, the F distribution with degrees of freedom (4, 9 ).
By using the statistical tool of geogebra It was determined that this area is 0.82, so it is concluded that the probability that the quotient of sample variances is less than or equal to 2 is 82%.
There are two manufacturing processes for thin sheets. The variability of the thickness should be as low as possible. 21 samples are taken from each process. The sample from process A has a standard deviation of 1.96 microns, while the sample from process B has a standard deviation of 2.13 microns. Which of the processes has the least variability? Use a rejection level of 5%.
The data are as follows: Sb = 2.13 with nb = 21; Sa = 1.96 with na = 21. This means that we have to work with an F distribution of (20, 20) degrees of freedom.
The null hypothesis implies that the population variance of both processes is identical, that is, σa ^ 2 / σb ^ 2 = 1. The alternative hypothesis would imply different population variances.
Then, under the assumption of identical population variances, the calculated F statistic is defined as: Fc = (Sb / Sa) ^ 2.
Since the rejection level has been taken as α = 0.05, then α / 2 = 0.025
The distribution F (0.025, 20.20) = 0.406, while F (0.975, 20.20) = 2.46.
Therefore, the null hypothesis will be true if the calculated F fulfills: 0.406≤Fc≤2.46. Otherwise the null hypothesis is rejected.
As Fc = (2.13 / 1.96) ^ 2 = 1.18 it is concluded that the Fc statistic is in the acceptance range of the null hypothesis with a certainty of 95%. In other words, with 95% certainty, both manufacturing processes have the same population variance..


Yet No Comments