
The inferential statistics or deductive statistics is one that deduces the characteristics of a population from samples taken from it, through a series of analysis techniques. With the information obtained, models are developed that then allow making predictions about the behavior of said population..
For this reason, inferential statistics has become the number one science in offering the support and instruments that countless disciplines require when making decisions..

Physics, chemistry, biology, engineering, and social sciences continually benefit from these tools when they create their models and design and implement experiments..
Article index
Statistics arose in ancient times due to the need of people to organize things and optimize resources. Before the invention of writing, records were kept of the number of people and available livestock, by means of symbols that were engraved in stone..
Later, the Chinese, Babylonian and Egyptian rulers left data on the amount of the crops and the number of inhabitants, engraved on clay tablets, columns and monuments..
When Rome exercised its dominion in the Mediterranean it was common for the authorities to carry out censuses every five years. In fact the word "statistics" comes from the Italian word statista, what does it mean to express.
At the same time, in America the great pre-Columbian empires also kept similar records.
During the Middle Ages the governments of Europe, as well as the church, registered ownership of land. Then they did the same with births, baptisms, marriages and deaths.
The English statistician John Graunt (1620-1674) was the first to make predictions based on such lists, such as how many people might die from certain diseases and the estimated proportion of male and female births. For this reason, he is considered the father of demography..
Later, with the advent of probability theory, statistics ceased to be a mere collection of organizational techniques and achieved an unsuspected scope as a predictive science..
Thus the experts could begin to develop models of the behavior of populations and with them deduce what things could happen to people, objects and even ideas.

Below we have the most relevant characteristics of this branch of statistics:
- Inferential statistics studies a population taking from it a representative sample.
- The selection of the sample is carried out by means of different procedures, the most suitable being those that choose the components at random. Thus, any element of the population has the same probability of being chosen and thus unwanted biases are avoided..
- To organize the information collected makes use of descriptive statistics.
- Statistical variables are calculated on the sample that are used to estimate the properties of the population..
- Inferential or deductive statistics makes use of probability theory to study random events, that is, those that arise fortuitously. Each event is assigned a certain probability of occurrence.
- It constructs hypotheses - assumptions - about the parameters of the population and contrasts them, to find out whether or not they are correct and also calculates the confidence level of the answer, that is, it offers a margin of error. The first procedure is called hypothesis testing, while the margin of error is the confidence interval.

Studying a population in its entirety could demand a great deal of resources in money, time and effort. It is preferable to take representative samples that are much more manageable, collect data from them, and create hypotheses or assumptions about sample behavior..
Once the hypotheses are established and their validity is tested, the results are extended to the population and used to make decisions..
They also help to create models of that population, to make projections for the future. That is why inferential statistics is a very useful science for:
These are ideal fields of application, since statistical techniques are applied with the idea of establishing various models of human behavior. Something that a priori is quite complicated, since numerous variables intervene.
In politics, it is widely used at election time to know the voting tendency of the electorate, in this way the parties design strategies.
Inferential statistics methods are widely used in Engineering, the most important applications being quality control and process optimization, for example improving times in the performance of tasks, as well as in the prevention of occupational accidents..
With deductive methods you can carry out projections about the operation of a company, the expected level of sales, as well as help when making decisions.
For example, its techniques can be used to estimate what will be the reaction of buyers to a new product, which is about to be launched on the market..
It also serves to assess how changes in people's consumption habits are, given important events, such as the COVID epidemic..
A simple deductive statistics problem is the following: a mathematics teacher is in charge of 5 sections of elementary algebra in a university and decides to use the average grades of just one of its sections to estimate the average of all.

Another possibility is to take a sample from each section, study its characteristics and extend the results to all sections..
The manager of a women's clothing store wants to know how much a certain blouse will sell during the summer season. To do this, it analyzes the sales of the garment during the first two weeks of the season and thus determines the trend..
There are several key concepts, including those that come from probability theory, that you need to be clear about in order to understand the full scope of these techniques. Some, as a population and sample, we have already been mentioning throughout the text.
An event or event is something that happens, and that can have several results. An example of an event could be to flip a coin and there are two possible outcomes: heads or tails.
It is the set of all possible outcomes of an event.
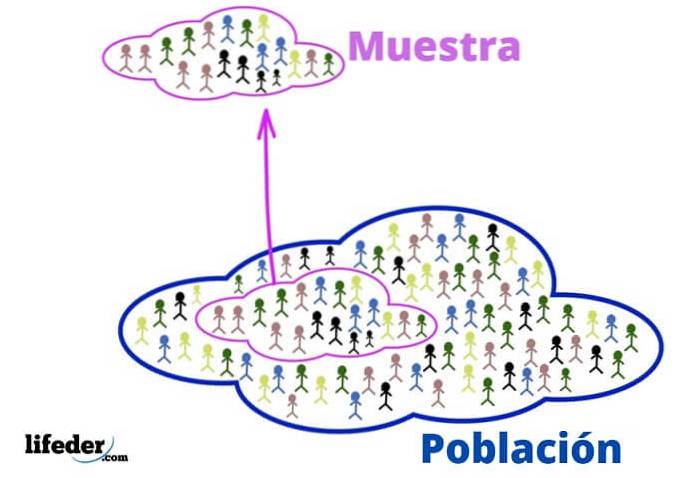
The population is the universe that you want to study. It is not necessarily about people or living beings, since the population, in statistics, can consist of objects or ideas.
For its part, the sample is a subset of the population, carefully extracted from it because it is representative..
It is the set of techniques by which a sample is selected from a given population. The sampling can be random if probabilistic methods are used to choose the sample, or non-probabilistic, if the analyst has his own selection criteria, according to his experience..
Set of values that can have the characteristics of the population. They are classified in various ways, for example they can be discrete or continuous. Also, taking into account their nature, they can be qualitative or quantitative..
Probability functions that describe the behavior of a large number of systems and situations observed in nature. The best known are the Gaussian or Gaussian bell distribution and the binomial distribution.
The estimation theory establishes that there is a relationship between the values of the population and those of the sample taken from that population. The parameters are the characteristics of the population that we do not know but want to estimate: for example, the mean and standard deviation.
For their part, statistics are the characteristics of the sample, for example its mean and standard deviation.
As an example, suppose that the population consists of all young people between 17 and 30 years of age in a community, and we want to know the proportion of those currently in higher education. This would be the population parameter to determine.
To estimate it, a random sample of 50 young people is selected and the proportion of them studying at a university or institute of higher education is calculated. This proportion is the statistic.
If after the study it is determined that 63% of the 50 young people are in higher education, this is the population estimate, made from the sample.
This is just one example of what inferential statistics can do. It is known as estimation, but there are also techniques for predicting statistical variables, as well as for making decisions.
It is a conjecture that is made regarding the value of the mean and the standard deviation of some characteristic of the population. Unless the population is fully examined, these are unknown values.
Are the assumptions made about the population parameters valid? To find out, it is verified whether the results from the sample support them or not, so it is necessary to design hypothesis tests.
These are the general steps to perform one:
Identify the type of distribution the population is expected to follow.
State two hypotheses, denoted as Hor and H1. The first is the null hypothesis in which we assume that the parameter has a certain value. The second is the alternative hypothesis which assumes a different value than the null hypothesis. If this is rejected, the alternative hypothesis is accepted.
Establish an acceptable margin for the difference between the parameter and the statistic. These will rarely turn out to be identical, although they are expected to be very close..
Propose a criterion to accept or reject the null hypothesis. For this, a test statistic is used, which can be the mean. If the mean value is within certain limits, the null hypothesis is accepted, otherwise it is rejected.
As a final step, it is decided whether or not to accept the null hypothesis..
Branches of statistics.
Statistical variables.
Population and sample.
Descriptive statistics.



Yet No Comments