The Absolute frecuency It is defined as the number of times that the same data is repeated within the set of observations of a numerical variable. The sum of all the absolute frequencies is equivalent to totaling the data.
When you have many values of a statistical variable, it is convenient to organize them appropriately to extract information about its behavior. Such information is given by the measures of central tendency and the measures of dispersion..
In the calculations of these measures, the data are represented through the frequency with which they appear in all the observations..
The following example shows how revealing the absolute frequency of each piece of data is. During the first half of May, these were the best-selling cocktail dress sizes from a well-known women's clothing store:
8; 10; 8; 4; 6; 10; 12; 14; 12; 16; 8; 10; 10; 12; 6; 6; 4; 8; 12; 12; 14; 16; 18; 12; 14; 6; 4; 10; 10; 18
How many dresses are sold in a particular size, for example size 10? Owners are interested in knowing to order.
Ordering the data makes it easier to count, there are exactly 30 observations in total, which ordered from the smallest size to the largest are as follows:
4; 4; 4; 6; 6; 6; 6; 8; 8; 8; 8; 10; 10; 10; 10; 10; 10; 12; 12; 12; 12; 12; 12; 14; 14; 14; 16; 16; 18; 18
And now it is evident that size 10 is repeated 6 times, therefore its absolute frequency is equal to 6. The same procedure is carried out to find out the absolute frequency of the remaining sizes..
Article index
The absolute frequency, denoted as fi, is equal to the number of times that a certain value Xi is within the group of observations.
Assuming that the total number of observations is N values, the sum of all the absolute frequencies must be equal to this number:
∑fi = f1 + Ftwo + F3 +... fn = N
If each value of fi divided by the total number of data N, we have the relative frequency Fr of the X valuei:
Fr = fi / N
Relative frequencies are values between 0 and 1, because N is always greater than any fi, but the sum must be equal to 1.
Multiplying each value of f by 100r you have the percentage relative frequency, whose sum is 100%:
Percentage relative frequency = (fi / N) x 100%
Also important is cumulative frequency Fi up to a certain observation, this is the sum of all the absolute frequencies up to and including said observation:
Fi = f1 + Ftwo + F3 +... fi
If the accumulated frequency is divided by the total number of data N, we have the cumulative relative frequency, which multiplied by 100 gives the percentage cumulative relative frequency.
To find the absolute frequency of a certain value that belongs to a data set, all of them are organized from lowest to highest and the number of times the value appears is counted.
In the example of dress sizes, the absolute frequency of size 4 is 3 dresses, that is f1 = 3. For size 6, 4 dresses were sold: ftwo = 4. In size 8 4 dresses were also sold, f3 = 4 and so on.
The total results can be represented in a table that shows the absolute frequencies of each one:
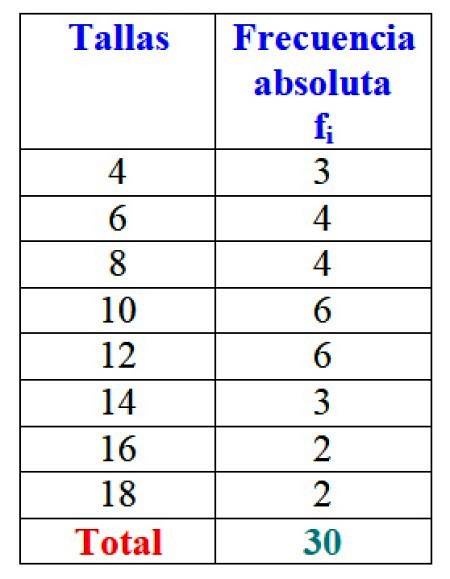
Obviously it is advantageous to organize the information and be able to access it at a glance, instead of working with individual data.
Important: note that when adding all the values of column fi you always get the total number of data. If not, you have to check the accounting, since there is an error.
The above table can be extended by adding the other frequency types in successive columns to the right:
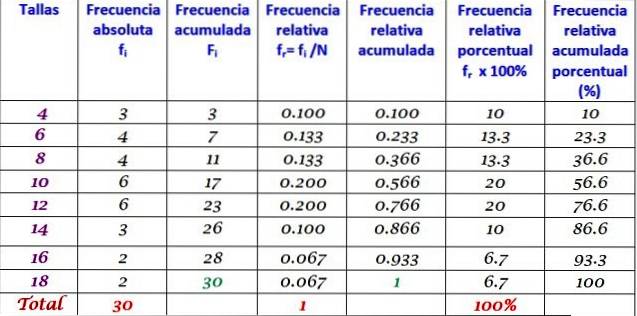
The frequency distribution is the result of organizing the data in terms of their frequencies. When working with many data, it is convenient to group them into categories, intervals or classes, each one with its respective frequencies: absolute, relative, accumulated and percentage..
The objective of doing them is to more easily access the information contained in the data, as well as to interpret it properly, which is not possible when they are presented in no order.
In the example of the sizes, the data is not grouped as it is not too many sizes and can be easily manipulated and accounted for. Qualitative variables can also be worked in this way, but when the data is very numerous, it is better to work by grouping them in classes.
To group your data into classes of equal size, consider the following:
-Class size, width or breadth: is the difference between the highest value in the class and the lowest.
The size of the class is decided by dividing the rank R by the number of classes to be considered. The range is the difference between the maximum value of the data and the smallest, like this:
Class size = Rank / Number of classes.
-Class limit: interval from the lower limit to the upper limit of the class.
-Class mark: is the midpoint of the interval, which is considered representative of the class. It is calculated with the semi-sum of the upper limit and the lower limit of the class.
-Number of classes: Sturges formula can be used:
Number of classes = 1 + 3,322 log N
Where N is the number of classes. As it is usually a decimal number, it is rounded to the next integer.
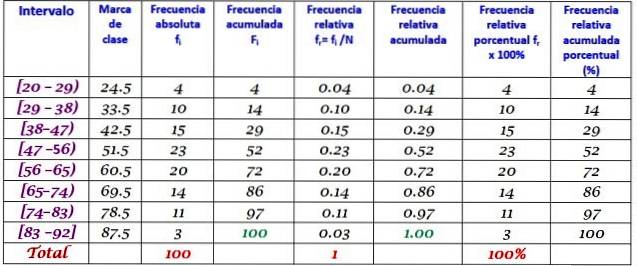
A machine in a large factory is out of operation due to recurring failures. The consecutive periods of inactivity time in minutes, of said machine, are recorded below, with a total of 100 data:
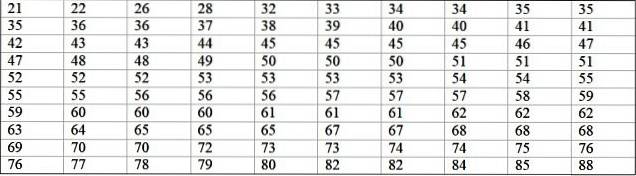
First the number of classes is determined:
Number of classes = 1 + 3,322 log N = 1 + 3.32 log 100 = 7.64 ≈ 8
Class size = Range / Number of classes = (88-21) / 8 = 8,375
It is also a decimal number, so 9 is taken as the class size.
The class mark is the average between the upper and lower limits of the class, for example for class [20-29) there is a mark of:
Class mark = (29 + 20) / 2 = 24.5
We proceed in the same way to find the class marks of the remaining intervals.
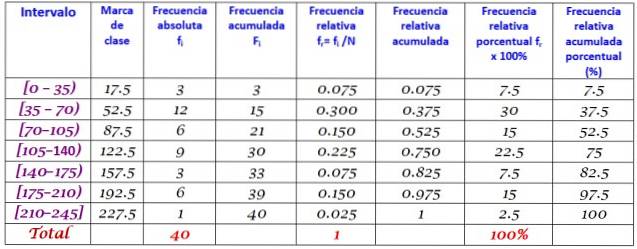
40 young people indicated that the time in minutes they spent on the internet last Sunday was the following, ordered in increasing order:
0; 12; twenty; 35; 35; 38; 40; Four. Five; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200; 220.
It is asked to construct the frequency distribution of these data.
The range R of the set of N = 40 data is:
R = 220 - 0 = 220
Applying the Sturges formula to determine the number of classes yields the following result:
Number of classes = 1 + 3,322 log N = 1 + 3.32 log 40 = 6.3
Since it is a decimal, the immediate integer is 7, therefore the data is grouped into 7 classes. Each class has a width of:
Class size = Rank / Number of classes = 220/7 = 31.4
A close and round value is 35, therefore a class width of 35 is chosen.
Class marks are calculated by averaging the upper and lower limits of each interval, for example, for the interval [0.35):
Class mark = (0 + 35) / 2 = 17.5
Proceed in the same way with the other classes.
Finally, the frequencies are calculated according to the procedure described above, resulting in the following distribution:



Yet No Comments