
The cumulative frequency is the sum of the absolute frequencies f, from the lowest to the one that corresponds to a certain value of the variable. In turn, the absolute frequency is the number of times an observation appears in the data set.
Obviously, the study variable must be sortable. And since the accumulated frequency is obtained by adding the absolute frequencies, it turns out that the accumulated frequency until the last data, must coincide with the total of them. Otherwise there is an error in the calculations.

Usually the cumulative frequency is denoted as Fi (or sometimes ni), to distinguish it from the absolute frequency fi and it is important to add a column for it in the table with which the data is organized, known as frequency table.
This makes it easier, among other things, to keep track of how much data was counted up to a certain observation..
A Fi it is also known as absolute cumulative frequency. If divided by the total data, we have the relative cumulative frequency, whose final sum must be equal to 1.
Article index
The cumulative frequency of a given value of variable Xi is the sum of the absolute frequencies f of all values less than or equal to it:
Fi = f1 + Ftwo + F3 +... fi
By adding all the absolute frequencies, the total number of data N is obtained, that is:
F1 + Ftwo + F3 +…. + Fn = N
The previous operation is written in a summarized way by means of the summation symbol ∑:
∑ Fi = N
The following frequencies can also be accumulated:
-Relative frequency: is obtained by dividing the absolute frequency fi between the total data N:
Fr = fi / N
If the relative frequencies from the lowest to the one corresponding to a certain observation are added, we have the cumulative relative frequency. The last value must be equal to 1.
-Percentage cumulative relative frequency: the accumulated relative frequency is multiplied by 100%.
F% = (fi / N) x 100%
These frequencies are useful to describe the behavior of the data, for example when finding the measures of central tendency.
To obtain the accumulated frequency, it is necessary to order the data and organize them in a frequency table. The procedure is illustrated in the following practical situation:
-In an online store that sells cell phones, the sales record of a certain brand for the month of March showed the following values per day:
1; two; 1; 3; 0; 1; 0; two; 4; two; 1; 0; 3; 3; 0; 1; two; 4; 1; two; 3; two; 3; 1; two; 4; two; 1; 5; 5; 3
The variable is the number of phones sold per day and it is quantitative. The data presented in this way is not so easy to interpret, for example the owners of the store might be interested in knowing if there is any trend, such as days of the week when the sales of that brand are higher..
Information like this and more can be obtained by presenting the data in an orderly manner and specifying the frequencies..
To calculate the cumulative frequency, the data is first ordered:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; two; two; two; two; two; two; two; two; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Then a table is built with the following information:
-The first column on the left with the number of phones sold, between 0 and 5 and in increasing order.
-Second column: absolute frequency, which is the number of days that 0 phones, 1 phone, 2 phones, and so on were sold.
-Third column: the accumulated frequency, consisting of the sum of the previous frequency plus the frequency of the data to be considered.
This column begins with the first data in the absolute frequency column, in this case it is 0. For the next value, add this with the previous one. It continues like this until reaching the last data of the accumulated frequency, which must coincide with the total data.
The following table shows the variable "number of telephones sold in a day", its absolute frequency and the detailed calculation of its accumulated frequency.
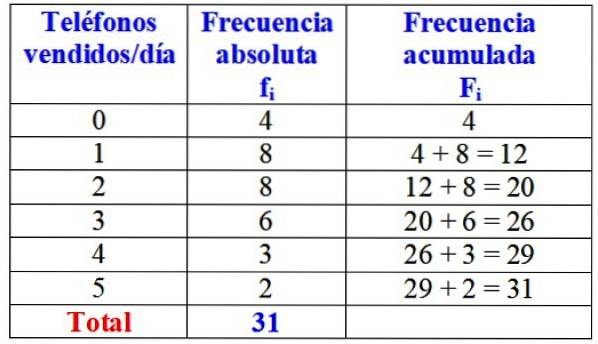
At a first glance, it could be stated that of the brand in question, one or two phones are almost always sold a day, since the highest absolute frequency is 8 days, which corresponds to these values of the variable. Only during 4 days of the month they did not sell a single phone.
As noted, the table is easier to examine than the individual data originally collected.
A cumulative frequency distribution is a table showing the absolute frequencies, the cumulative frequencies, the cumulative relative frequencies, and the cumulative percentage frequencies..
Although there is the advantage of organizing the data in a table like the previous one, if the number of data is very large, it may not be enough to organize them as shown above, because if there are many frequencies, it still becomes difficult to interpret.
The problem can be remedied by building a frequency distribution by intervals, a useful procedure when the variable takes on a large number of values or if it is a continuous variable.
Here the values are grouped into intervals of equal amplitude, called class. The classes are characterized by having:
-Class limit: are the extreme values of each interval, there are two, the upper limit and the lower limit. In general, the upper limit does not belong to the interval but to the next one, while the lower limit does belong.
-Class mark: is the midpoint of each interval, and is taken as the representative value of it.
-Class width: It is calculated by subtracting the value of the largest and smallest data (range) and dividing by the number of classes:
Class width = Range / Number of classes
The elaboration of the frequency distribution is detailed below..
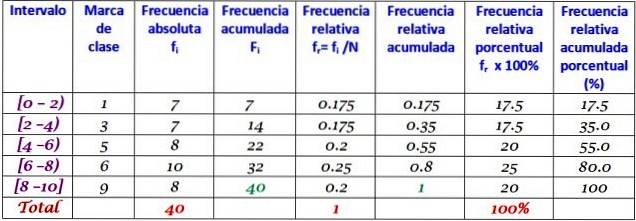
This data set corresponds to 40 marks of a mathematics test, on a scale of 0 to 10:
0; 0; 0; 1; 1; 1; 1; two; two; two; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9; 10; 10.
A frequency distribution can be made with a certain number of classes, for example 5 classes. It should be borne in mind that when using many classes, the data is not easy to interpret either and the sense of carrying out the grouping is lost.
And if, on the contrary, they are grouped into very few, then the information is diluted and part of it is lost. It all depends on the amount of data you have.
In this example, it is a good idea to have two scores in each interval, since there are 10 scores and 5 classes will be created. The range is the subtraction between the highest and lowest grade, the class width being:
Class width = (10-0) / 5 = 2
The intervals are closed on the left and open on the right (except the last one), which is symbolized by brackets and parentheses respectively. They are all the same width, but it is not mandatory, although it is most often.
Each interval contains a certain amount of elements or absolute frequency, and in the next column is the accumulated frequency, in which the sum is carried. The table also shows the relative frequency fr (absolute frequency between the total number of data) and the percentage relative frequency fr × 100%.
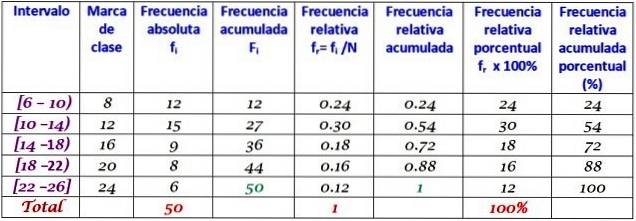
One company made daily calls to its customers during the first two months of the year. The data is as follows:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Group in 5 classes and build the table with the frequency distribution.
The class width is:
(26-6) / 5 = 4
Try to figure it out before you see the answer.

Yet No Comments