The degrees of freedom in statistics they are the number of independent components of a random vector. If the vector has n components and there are p linear equations that relate their components, then the degree of freedom is n-p.
The concept of degrees of freedom It also appears in theoretical mechanics, where roughly they are equivalent to the dimension of space where the particle moves, minus the number of bonds..
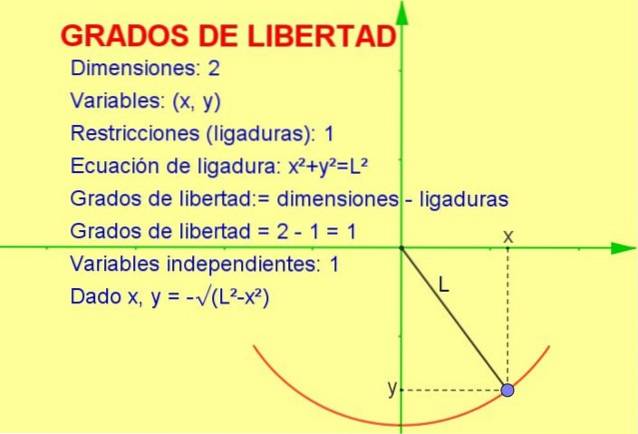
This article will discuss the concept of degrees of freedom applied to statistics, but a mechanical example is easier to visualize in geometric form.
Article index
Depending on the context in which it is applied, the way to calculate the number of degrees of freedom may vary, but the underlying idea is always the same: total dimensions minus number of restrictions.
Let's consider an oscillating particle tied to a string (a pendulum) that moves in the vertical x-y plane (2 dimensions). However, the particle is forced to move on the circumference of radius equal to the length of the chord.
Since the particle can only move on that curve, the number of degrees of freedom is 1. This can be seen in figure 1.
The way to calculate the number of degrees of freedom is by taking the difference of the number of dimensions minus the number of constraints:
degrees of freedom: = 2 (dimensions) - 1 (ligature) = 1
Another explanation that allows us to arrive at the result is the following:
-We know that the position in two dimensions is represented by a point of coordinates (x, y).
-But since the point must satisfy the equation of the circumference (xtwo + Ytwo = Ltwo) for a given value of the variable x, the variable y is determined by said equation or restriction.
Thus, only one of the variables is independent and the system has one (1) degree of freedom.
To illustrate what the concept means, suppose the vector
x = (x1, xtwo,..., xn)
What represents the sample of n normally distributed random values. In this case the random vector x have n independent components and therefore it is said that x have n degrees of freedom.
Now let's build the vector r of waste
r = (x1 -
Where
So the sum
(x1 -
It is an equation that represents a constraint (or binding) on the elements of the vector r of the residues, since if n-1 components of the vector are known r, the constraint equation determines the unknown component.
Therefore the vector r of dimension n with the restriction:
∑ (xi -
Have (n - 1) degrees of freedom.
Again it is applied that the calculation of the number of degrees of freedom is:
degrees of freedom: = n (dimensions) - 1 (constraints) = n-1
The variance stwo is defined as the mean of the square of the deviations (or residuals) of the sample of n data:
stwo = (r•r) / (n-1)
where r is the vector of the residuals r = (x1 -
stwo = ∑ (xi -
In any case, it should be noted that when calculating the mean of the square of the residuals, it is divided by (n-1) and not by n, since as discussed in the previous section, the number of degrees of freedom of the vector r is (n-1).
If for the calculation of the variance were divided by n instead of (n-1), the result would have a bias that is very significant for values of n under 50.
In the literature, the variance formula also appears with the divisor n instead of (n-1), when it comes to the variance of a population.
But the set of the random variable of the residuals, represented by the vector r, Although it has dimension n, it only has (n-1) degrees of freedom. However, if the number of data is large enough (n> 500), both formulas converge to the same result.
Calculators and spreadsheets provide both versions of the variance and the standard deviation (which is the square root of the variance).
Our recommendation, in view of the analysis presented here, is to always choose the version with (n-1) each time it is required to calculate the variance or standard deviation, to avoid biased results..
Some probability distributions in continuous random variable depend on a parameter called degree of freedom, is the case of the Chi square distribution (χtwo).
The name of this parameter comes precisely from the degrees of freedom of the underlying random vector to which this distribution applies.
Suppose we have g populations, from which samples of size n are taken:
X1 = (x11, x1two,… X1n)
X2 = (x21, x2two,… X2n)
... .
Xj = (xj1, xjtwo,… Xjn)
... .
Xg = (xg1, xgtwo,… Xgn)
A population j what has average
The standardized or normalized variable zji is defined as:
zji = (xji -
And the vector Zj is defined like this:
Zj = (zj1, zjtwo,..., zji,..., zjn) and follows the standardized normal distribution N (0,1).
So the variable:
Q = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
follow the distribution χtwo(g) called the chi square distribution with degree of freedom g.
When you want to make a hypothesis test based on a certain set of random data, you need to know the number of degrees of freedom g to be able to apply the Chi square test.
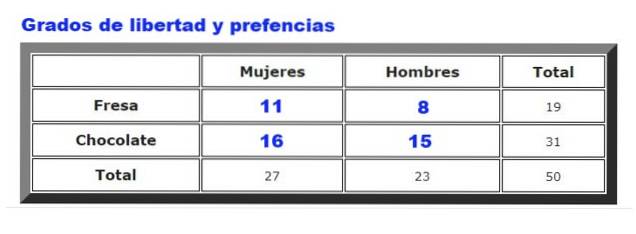
As an example, the data collected on the preferences of chocolate or strawberry ice cream among men and women in a certain ice cream parlor will be analyzed. The frequency with which men and women choose strawberry or chocolate is summarized in figure 2.
First, the table of expected frequencies is calculated, which is elaborated by multiplying the total rows for him total columns, divided by total data. The result is shown in the following figure:

Then we proceed to calculate the Chi square (from the data) using the following formula:
χtwo = ∑ (For - Fand)two / Fand
Where For are the observed frequencies (Figure 2) and Fand are the expected frequencies (Figure 3). The summation goes over all the rows and columns, which in our example give four terms.
After doing the operations you get:
χtwo = 0.2043.
Now it is necessary to compare with the theoretical Chi square, which depends on the number of degrees of freedom g.
In our case this number is determined as follows:
g = (# rows - 1) (# columns - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
It turns out that the number of degrees of freedom g in this example is 1.
If you want to verify or reject the null hypothesis (H0: there is no correlation between TASTE and GENDER) with a significance level of 1%, proceed to calculate the theoretical Chi-square value with degree of freedom g = 1.
The value that makes the accumulated frequency is (1 - 0.01) = 0.99, that is to say 99%, is searched. This value (which can be obtained from the tables) is 6.636.
As the theoretical Chi exceeds the calculated one, then the null hypothesis is verified.
That is, with the data collected, Not observed relationship between the variables TASTE and GENDER.



Yet No Comments