The measures of central tendency, dispersion and position, are values that are used to properly interpret a set of statistical data. These can be worked directly, as they are obtained from the statistical study, or they can be organized in groups of equal frequency, facilitating the analysis..
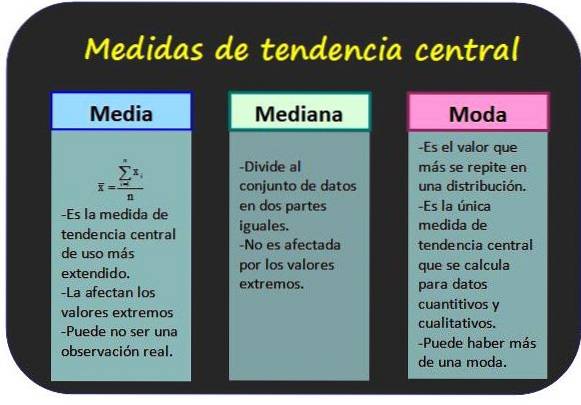
They allow knowing around which values the statistical data are grouped.
It is also known as the average of the values of a variable and is obtained by adding all the values and dividing the result by the total number of data.
Let be a variable x of which we have n data without organizing or grouping, its arithmetic mean is calculated as follows:
And in summation notation:
The owners of a mountain tourist inn have the intention of knowing how many days on average the visitors stay in the facilities. For this, a record of the days of permanence of 20 groups of tourists was kept, obtaining the following data:
1; 1; two; two; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; two; two; 3; 4; 1
The average number of days tourists stay is:
If the data of the variable are organized in a table of absolute frequencies fi and the class centers are x1, xtwo,..., xn, the mean is calculated by:
In summation notation:
The median of a group of n values of the variable x is the central value of the group, provided the values are ordered in increasing order. In this way, half of all values are less than the mode and the other half are greater..
The following cases may occur:
-Number n of values of the variable x odd: the median is the value that is right in the middle of the group of values:
-Number n of values of the variable x pair: in this case the median is calculated as the average of the two central values of the data group:
To find the median of the data from the tourist hostel, they are first ordered from lowest to highest:
1; 1; 1; 1; 1; 1; 1; two; two; two; two; 3; 3; 3; 4; 4; 4; 4; 5; 5
The number of data is even, therefore there are two central data: X10 and Xeleven and since both are worth 2, their average is also.
Median = 2
The following formula is used:
The symbols in the formula mean:
-c: width of the interval that contains the median
-BM: lower bound of the same interval
-Fm: number of observations contained in the interval to which the median belongs.
-n: total data.
-FBM: number of observations before of the interval containing the median.
The mode for ungrouped data is the value with the highest frequency, while for grouped data it is the class with the highest frequency. Fashion is considered the most representative data or class of the distribution.
Two important characteristics of this measure is that a data set can have more than one mode, and the mode can be determined for both quantitative and qualitative data..
Continuing with the data of the tourist parador, the one that is repeated the most is 1, therefore, the most usual thing is that tourists stay 1 day in the parador.
Measures of dispersion describe how clustered the data is around the central measures.
It is calculated by subtracting the largest data and the smallest data. If this difference is large, it is a sign that the data is scattered, while small values indicate that the data is close to the mean..
The range for the data of the tourist parador is:
Range = 5−1 = 4
To find the variance stwo It is necessary to first know the arithmetic mean, then the squared difference between each piece of data and the mean is calculated, all of them are added and divided by the total number of observations. These differences are known as deviations.
The variance, which is always positive (or zero), indicates how far the observations are from the mean: if the variance is high, the values are more dispersed than when the variance is small.
The variance for the data from the tourist hostel is:
1; 1; two; two; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; two; two; 3; 4; 1
To find the variance of a grouped data set, we require: i) the mean, ii) the frequency fi which is the total data in each class and iii) xi or class value:
The standard deviation is the positive square root of the variance, so it has an advantage over the variance: it comes in the same units as the variable under study and thus you have a more direct idea of how close or far the variable is from average.
It is determined simply by finding the square root of the variance for ungrouped data:
The standard deviation for the data from the tourist hostel is:
s = √ (stwo) = √1.95 = 1.40
It is calculated by finding the square root of the variance for grouped data:
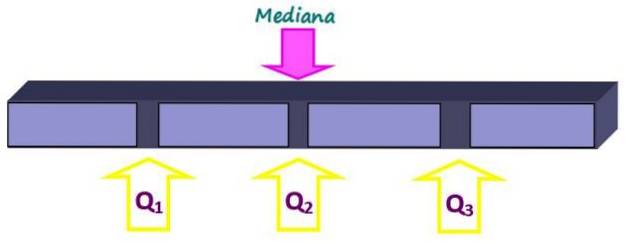
Measures of position divide an ordered set of data into pieces of equal size. The median, in addition to being a measure of central tendency, is also a measure of position, since it divides the whole into two equal parts. But smaller parts can be obtained with quartiles, deciles and percentiles.
The quartiles divide the set into four equal parts, each containing 25% of the data. They are denoted as Q1, Qtwo and Q3 and the median is the quartile Qtwo. In this way, 25% of the data is below the Q quartile.1, 50% below the Q quartiletwo or median and 75% below the Q quartile3.
The data is ordered and the total is divided into 4 groups with the same number of data each. The position of the first quartile is found by:
Q1 = (n + 1) / 4
Where n is the total data. If the result is an integer, the data corresponding to that position is located, but if it is decimal, the data corresponding to the integer part is averaged with the next, or for greater precision it is linearly interpolated between said data.
The position of the first quartile Q1 for the data of the tourist parador is:
Q1 = (n + 1) / 4 = (20 + 1) / 4 = 5.25
This is the position of quartile 1 and since the result is decimal, the data X is searched5 and X6, which are respectively X5 = 1 and X6 = 1 and are averaged, resulting in:
First quartile = 1
1; 1; 1; 1; 1; 1; 1; two; two; two; two; 3; 3; 3; 4; 4; 4; 4; 5; 5.
The position of the second quartile Qtwo it is:
Qtwo = 2 (n + 1) / 4 = 10.5
What is the average between X10 and Xeleven and matches the median:
Second quartile = Median = 2
The position of the third quartile is calculated by:
Q3 = 3 (n + 1) / 4 = 3 (20 + 1) / 4 = 15.75
It is also decimal, therefore X is averagedfifteen and X16:
1; 1; 1; 1; 1; 1; 1; two; two; two; two; 3; 3; 3; 4; 4; 4; 4; 5; 5.
But since both are worth 4:
Third quartile = 4
The general formula for the position of quartiles in ungrouped data is:
Qk = k (n + 1) / 4
With k = 1,2,3.
They are calculated in a similar way to the median:

The explanation of the symbols is:
-BQ: lower boundary of the interval containing the quartile
-c: width of that interval
-Fwhat: number of observations contained in the quartile interval.
-n: total data.
-FBQ: number of data before of the interval containing the quartile.
The deciles and percentiles divide the data set into 10 equal parts and 100 equal parts respectively, and their calculation is carried out in a similar way to that of the quartiles.
The formulas are used respectively:
Dk = k (n + 1) / 10
With k = 1,2,3… 9.
Decile D5 must be equal to the median.
Pk = k (n + 1) / 100
With k = 1,2,3… 99.
The P percentilefifty must be equal to the median.
In the example of the tourist inn, the position of the D3 it is:
D3 = 3 (20 + 1) / 10 = 6.3
Since it is a decimal number, X is averaged6 and X7, both equal to 1:
1; 1; 1; 1; 1; 1; 1; two; two; two; two; 3; 3; 3; 4; 4; 4; 4; 5; 5
It means that 3 tenths of the data is below X7 = 1 and the rest above.
The formulas are analogous to those for quartiles. D is used to denote deciles and P for percentiles, and the symbols are interpreted similarly:
When the data is symmetrically distributed and the distribution is unimodal, there is a rule called empirical rule or rule 68 - 95 - 99, that groups them in the following intervals:
In what interval is 95% of the data of the tourist parador?
They are in the interval: [2.5−1.40; 2.5 + 1.40] = [1.1; 3.9].



Yet No Comments