A empirical rule It is the result of practical experience and real life observation. For example, it is possible to know which species of birds can be observed in certain places at each time of the year and from that observation a "rule" can be established that describes the life cycles of these birds..
In statistics, the empirical rule refers to the way in which observations are grouped around a central value, the mean or average, in units of standard deviation.

Suppose we have a group of people with an average height of 1.62 meters and a standard deviation of 0.25 meters, then the empirical rule would allow defining, for example, how many people would be in an interval of the mean plus or minus one standard deviation?
According to the rule, 68% of the data is more or less one standard deviation from the mean, that is, 68% of the people in the group will have a height between 1.37 (1.62-0.25) and 1.87 (1.62 + 0.25 ) meters.
Article index
The empirical rule is a generalization of the Tchebyshev Theorem and the Normal Distribution.
Tchebyshev's theorem says that: for some value of k> 1, the probability that a random variable falls between the mean minus k times the standard deviation, and the mean plus k times, the standard deviation is greater than or equal to ( 1 - 1 / ktwo).
The advantage of this theorem is that it applies to discrete or continuous random variables with any probability distribution, but the rule defined from it is not always very precise, since it depends on the symmetry of the distribution. The more skewed the distribution of the random variable, the less adjusted to the rule will be its behavior.
The empirical rule defined from this theorem is:
If k = √2, it is said that 50% of the data are in the interval: [µ - √2 s, µ + √2 s]
If k = 2, it is said that 75% of the data are in the interval: [µ - 2 s, µ + 2 s]
If k = 3, it is said that 89% of the data are in the interval: [µ - 3 s, µ + 3 s]
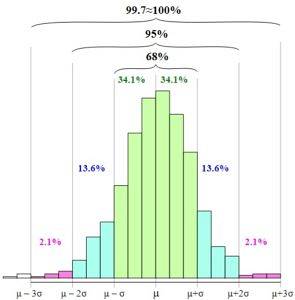
The normal distribution, or Gaussian bell, allows to establish the Empirical Rule or Rule 68 - 95 - 99.7.
The rule is based on the probabilities of occurrence of a random variable in intervals between the mean minus one, two or three standard deviations and the mean plus one, two or three standard deviations..
The empirical rule defines the following intervals:
68.27% of the data are in the interval: [µ - s, µ + s]
95.45% of the data are in the interval: [µ - 2s, µ + 2s]
99.73% of the data are in the interval: [µ - 3s, µ + 3s]
In the figure you can see how these intervals are presented and the relationship between them when increasing the width of the base of the graph.
Therefore, the application of the empirical rule in scale of a standard normal variable, z, defines the following intervals:
68.27% of the data are in the interval: [-1, 1]
95.45% of the data are in the interval: [-2, 2]
99.73% of the data are in the interval: [-3, 3]
The empirical rule allows abbreviated calculations when working with a normal distribution.
Suppose that a group of 100 college students has an average age of 23 years, with a standard deviation of 2 years. What information does the empirical rule allow?
Applying the empirical rule involves following the steps:
Since the mean is 23 and the standard deviation is 2, then the intervals are:
[µ - s, µ + s] = [23 - 2, 23 + 2] = [21, 25]
[µ - 2s, µ + 2s] = [23 - 2 (2), 23 + 2 (2)] = [19, 27]
[µ - 3s, µ + 3s] = [23 - 3 (2), 23 + 3 (2)] = [17, 29]
(100) * 68.27% = 68 students approximately
(100) * 95.45% = 95 students approximately
(100) * 99.73% = approximately 100 students
At least 68 students are between the ages of 21 and 25.
At least 95 students are between the ages of 19 and 27.
Almost 100 students are between 17 and 29 years old.
The empirical rule is a quick and practical way to analyze statistical data, becoming more and more reliable as the distribution approaches symmetry.
Its usefulness depends on the field in which it is used and the questions that are presented. It is very useful to know that the occurrence of values of three standard deviations below or above the mean is almost unlikely, even for non-normal distribution variables, at least 88.8% of cases are in the interval of three sigma.
In the social sciences, a generally conclusive result is the interval of the mean plus or minus two sigma (95%), whereas in particle physics, a new effect requires a five sigma interval (99.99994%) to be considered a discovery..
In a wildlife reserve it is estimated that there are an average of 16,000 rabbits with a standard deviation of 500 rabbits. If the distribution of the variable 'number of rabbits in the reserve' is unknown, is it possible to estimate the probability that the rabbit population is between 15,000 and 17,000 rabbits?
The interval can be presented in these terms:
15000 = 16000 - 1000 = 16000 - 2 (500) = µ - 2 s
17000 = 16000 + 1000 = 16000 + 2 (500) = µ + 2 s
Therefore: [15000, 17000] = [µ - 2 s, µ + 2 s]
Applying Tchebyshev's theorem, there is a probability of at least 0.75 that the rabbit population in the wildlife reserve is between 15,000 and 17,000 rabbits..
The average weight of one-year-old children in a country is normally distributed with a mean of 10 kilograms and a standard deviation of approximately 1 kilogram.
a) Estimate the percentage of one-year-old children in the country that have an average weight between 8 and 12 kilograms.
8 = 10 - 2 = 10 - 2 (1) = µ - 2 s
12 = 10 + 2 = 10 + 2 (1) = µ + 2 s
Therefore: [8, 12] = [µ - 2s, µ + 2s]
According to the empirical rule, it can be affirmed that 68.27% of one-year-old children in the country have between 8 and 12 kilograms of weight.
b) What is the probability of finding a one-year-old child weighing 7 kilograms or less??
7 = 10 - 3 = 10 - 3 (1) = µ - 3 s
It is known that 7 kilograms of weight represents the value µ - 3s, as well as it is known that 99.73% of children are between 7 and 13 kilograms of weight. That leaves only 0.27% of the total children for the extremes. Half of them, 0.135%, are 7 kilograms or less and the other half, 0.135%, are 11 kilograms or more.
So, it can be concluded that there is a probability of 0.00135 that a child weighs 7 kilograms or less.
c) If the country's population reaches 50 million inhabitants and 1-year-old children represent 1% of the country's population, how many one-year-old children will weigh between 9 and 11 kilograms?
9 = 10 - 1 = µ - s
11 = 10 + 1 = µ + s
Therefore: [9, 11] = [µ - s, µ + s]
According to the empirical rule, 68.27% of the one-year-olds in the country are in the interval [µ - s, µ + s]
There are 500,000 one-year-olds in the country (1% of 50 million), so 341,350 children (68.27% of 500,000) weigh between 9 and 11 kilograms.



Yet No Comments