The class mark, Also known as the midpoint, it is the value that is in the center of a class, which represents all the values that are in that category. Fundamentally, the class mark is used to calculate certain parameters, such as the arithmetic mean or the standard deviation..
So the class mark is the midpoint of any interval. This value is also very useful to find the variance of a set of data already grouped into classes, which in turn allows us to understand how far from the center these specific data are.

Article index
To understand what a class mark is, the concept of frequency distribution is necessary. Given a set of data, a frequency distribution is a table that divides the data into a number of categories called classes..
Said table shows the quantity of elements that belongs to each class; the latter is known as frequency.
In this table, part of the information that we obtain from the data is sacrificed, since instead of having the individual value of each element, we only know that it belongs to that class.
On the other hand, we gain a better understanding of the data set, since in this way it is easier to appreciate established patterns, which facilitates the manipulation of said data..
To make a frequency distribution, we must first determine the number of classes we want to take and choose their class limits..
The choice of how many classes to take should be convenient, taking into account that a small number of classes can hide information about the data we want to study and a very large one can generate too many details that are not necessarily useful..
The factors that we must take into account when choosing how many classes to take are several, but among these two stand out: the first is to take into account how much data we have to consider; the second is to know how large the range of the distribution is (that is, the difference between the largest and smallest observation).
After having the classes already defined, we proceed to count how much data exists in each class. This number is called the frequency of classes and is denoted by fi.
As we had previously said, we have that a frequency distribution loses the information that comes individually from each data or observation. For this reason, a value is sought that represents the entire class to which it belongs; this value is the class mark.
The class mark is the core value that a class represents. It is obtained by adding the limits of the interval and dividing this value by two. We could express this mathematically as follows:
xi= (Lower limit + Upper limit) / 2.
In this expression xi denotes the mark of the i-th class.
Given the following data set, give a representative frequency distribution and get the mark of corresponding classes.

Since the data with the highest numerical value is 391 and the lowest is 221, we have that the range is 391 -221 = 170.
We will choose 5 classes, all with the same size. One way to choose classes is as follows:

Note that each data is in a class, these are disjoint and have the same value. Another way to choose the classes is by considering the data as part of a continuous variable, which could reach any real value. In this case we can consider classes of the form:
205-245, 245-285, 285-325, 325-365, 365-405
However, this way of grouping data can present some borderline ambiguities. For example, in the case of 245 the question arises: which class does it belong to, the first or the second?
To avoid this confusion, an endpoint convention is made. In this way, the first class will be the interval (205,245], the second (245,285], and so on.

Once the classes are defined, we proceed to calculate the frequency and we have the following table:
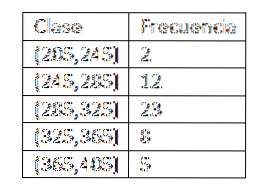
After obtaining the frequency distribution of the data, we proceed to find the class marks of each interval. In effect, we have to:
x1= (205+ 245) / 2 = 225
xtwo= (245+ 285) / 2 = 265
x3= (285+ 325) / 2 = 305
x4= (325+ 365) / 2 = 345
x5= (365+ 405) / 2 = 385
We can represent this by the following graph:
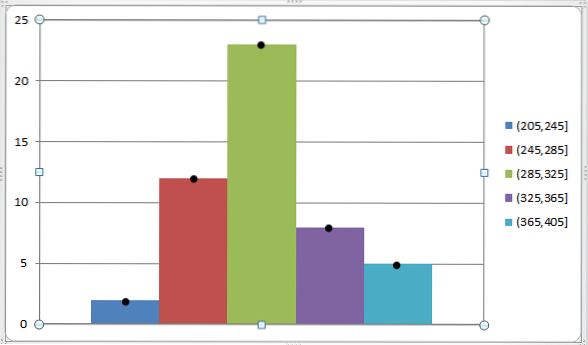
As mentioned previously, the class mark is very functional to find the arithmetic mean and the variance of a data group that has already been grouped into different classes..
We can define the arithmetic mean as the sum of the observations obtained between the sample size. From a physical point of view, its interpretation is like the equilibrium point of a data set.
Identifying an entire data set by a single number can be risky, so the difference between this breakeven point and the actual data must also be taken into account. These values are known as deviation from the arithmetic mean, and with these we seek to determine how much the arithmetic mean of the data varies..
The most common way to find this value is by variance, which is the average of the squares of the deviations from the arithmetic mean.
To calculate the arithmetic mean and variance of a set of data grouped in a class we use the following formulas, respectively:
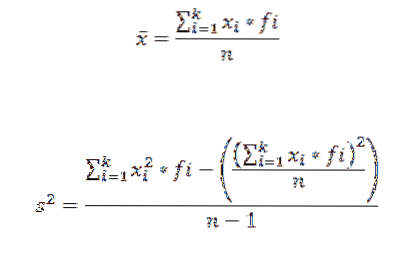
In these expressions xi is the i-th class mark, fi represents the corresponding frequency and k the number of classes in which the data were grouped.
Making use of the data given in the previous example, we have that we can expand a little more the data of the frequency distribution table. You get the following:
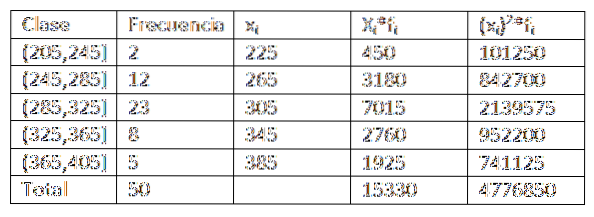
Then, by substituting the data in the formula, we are left with the arithmetic mean is:
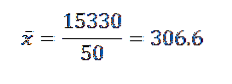
Its variance and standard deviation are:
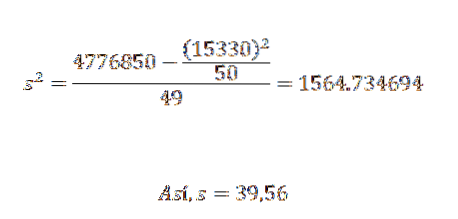
From this we can conclude that the original data have an arithmetic mean of 306.6 and a standard deviation of 39.56..

Yet No Comments